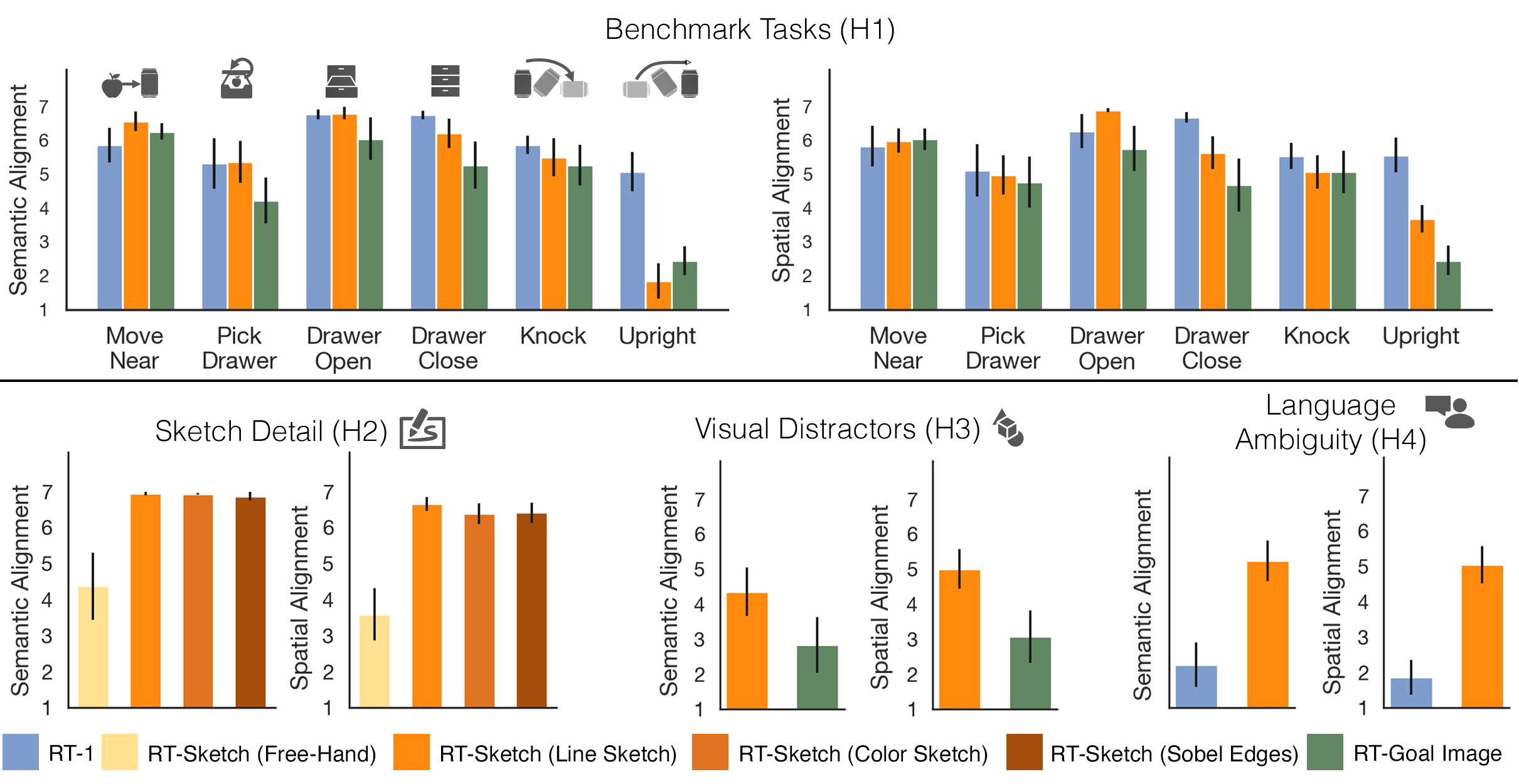
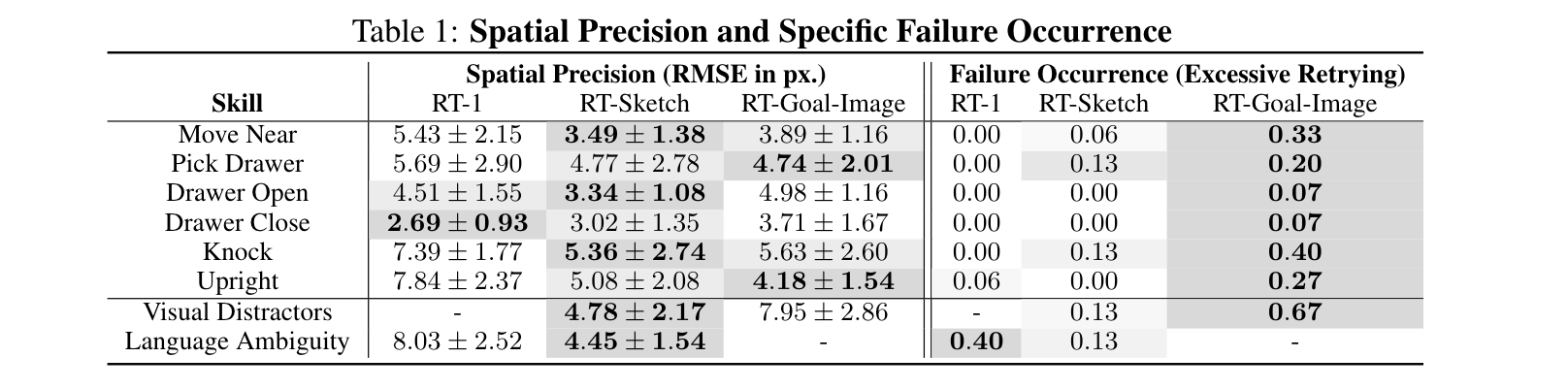
Dataset Generation & Training
GAN Output
+ Thickness Augmentation
+ Color Augmentation
+ Affine Augmentation
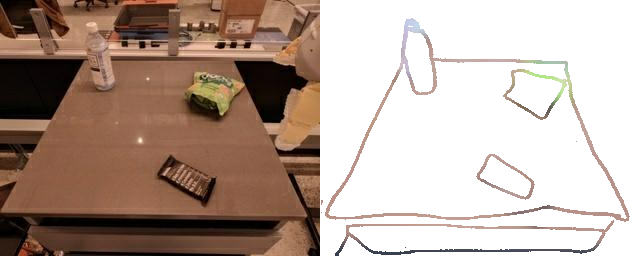
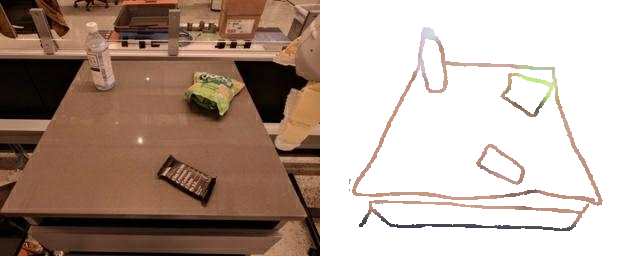
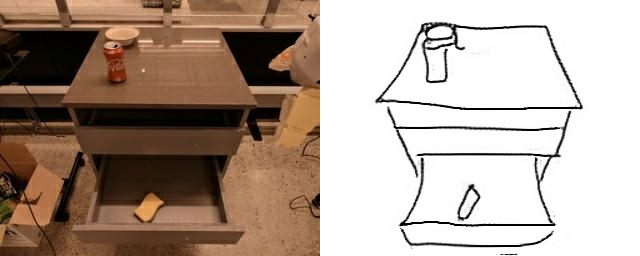
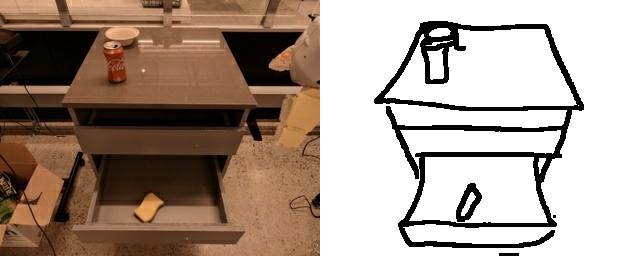
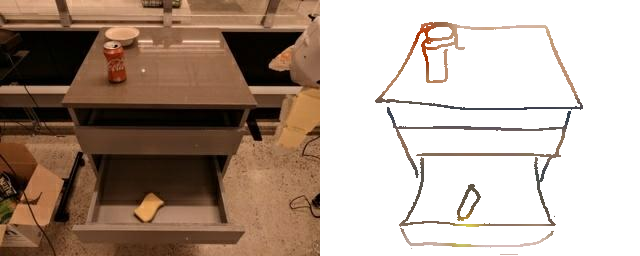
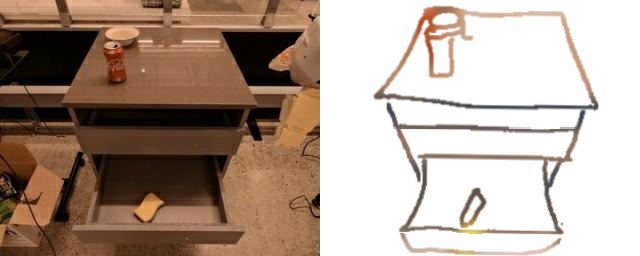
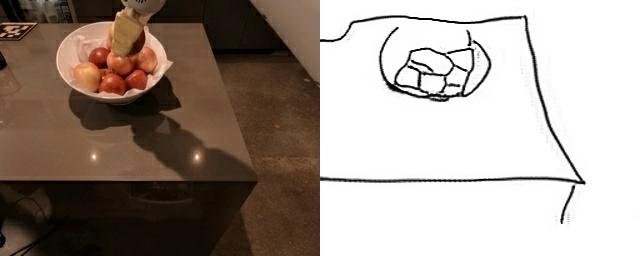

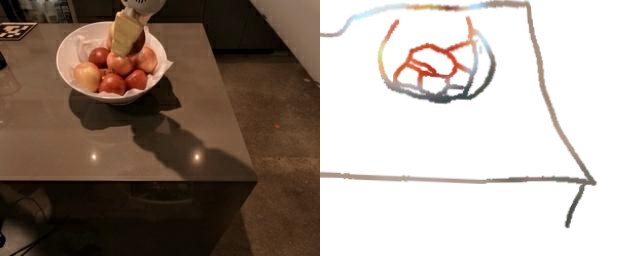
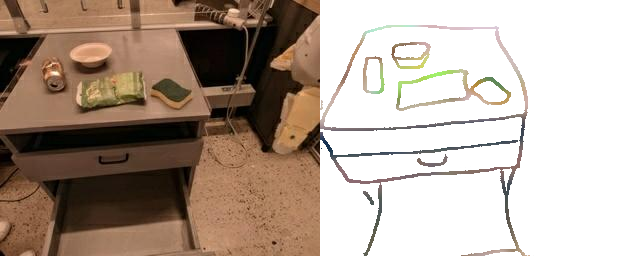

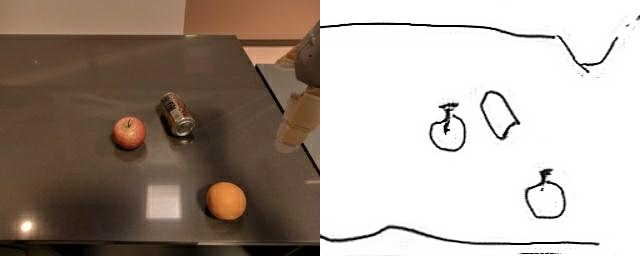
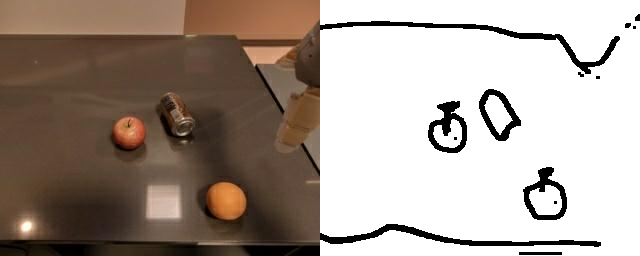
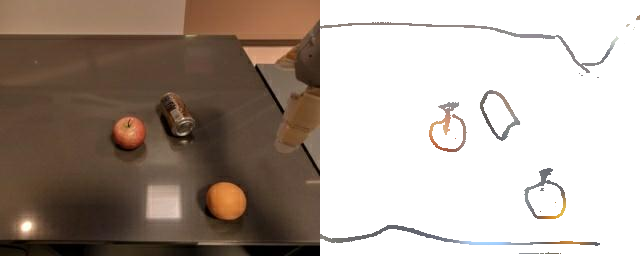
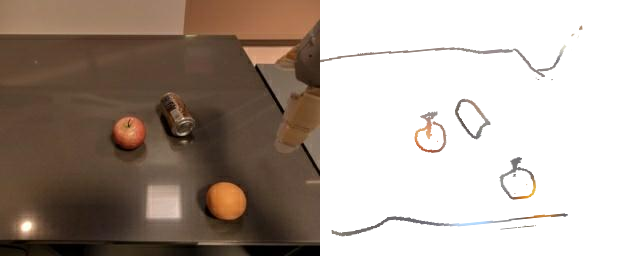
Training a sketch-conditioned IL policy requires collecting a dataset of trajectories paired with sketches representing the goal state. Since this is infeasible to collect manually at scale, we first train an image-to-sketch GAN translation network which automatically converts images into sketches. We additionally augment these generated sketches with various colorspace and affine transforms, to simulate variations in hand-drawn sketches. Using this network, we automatically convert hindsight-relabeled goal images from robot trajectories into goal sketches. The results are visualized above.
To train RT-Sketch, we sample an episode from a pre-recorded dataset of robot trajectories. Treating the last observation in the trajectory as a goal image, we convert this goal image to either a GAN-generated goal sketch, a colorized sketch, or an edge-detected image. We concatenate this goal representation with the history of RGB observations in the trajectory. Finally, the concatenated inputs serve as input to RT-Sketch, which outputs tokenized actions. The purpose of training on the varied input types is to encourage the policy to afford different levels in input sketch specificity.