Towards Multimodal Goal Specification
Language Alone
Sketch Alone
Sketch + Language
Wrong placement location
Not upright
Upright, correctly placed
"place the pepsi can upright"
"place the pepsi can upright"
Wrong placement location
Correct placement
Correct placement
"place the orange on the counter"
"place the orange on the counter"
We are excited by the prospect of multimodal goal specification to help resolve ambiguity from a single modality alone, and provide experiments to demonstrate that sketch-and-language conditioning can be favorable to either modality alone. We train a sketch-and-language conditioned model which uses FiLM along with EfficientNet layers to tokenize both visual input and language at the input. Here, we see that while language alone (i.e. "place the can upright") can be ambiguous in terms of spatial placement, and a sketch alone does not encourage reorientation, the joint policy is better able to address the limitations of either modality alone. Similarly, for the Pick Drawer skill, the sketch-conditioned and sketch-and-language-conditioned policies are more precisely able to place the orange on the counter as desired.
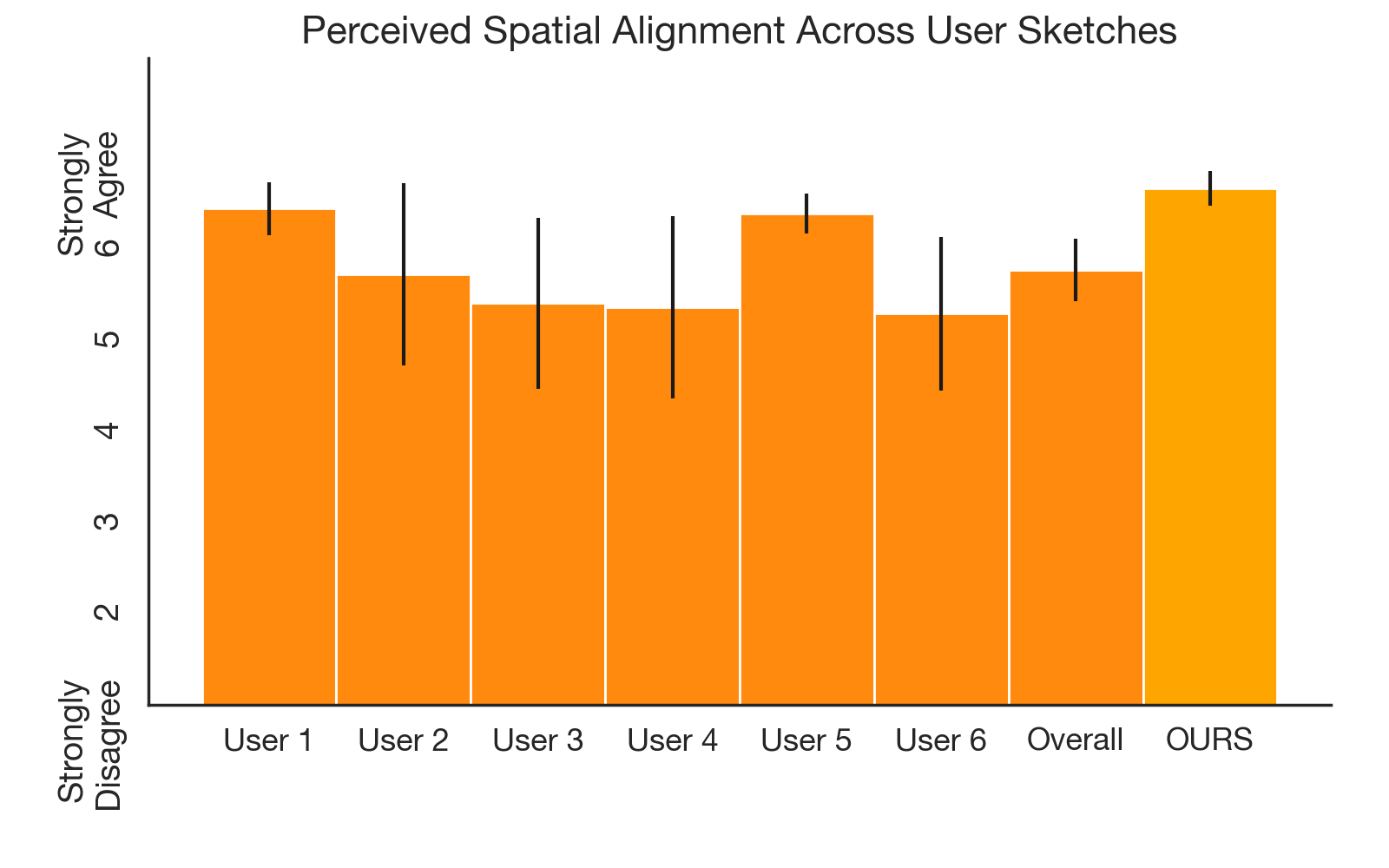
Robustness to Sketches Drawn by Different People
We evaluate whether RT-Sketch can generalize to sketches drawn by different individuals and handle stylistic variations via 22 human evaluators who provide Likert ratings. Across 30 sketches drawn by 6 different individuals using line sketching (tracing), RT-Sketch achieves high spatial alignment without a significant dropoff in performance between individuals, or compared to our original sketches used in evaluation. We provide the sketches drawn by the 6 different individuals and the corresponding robot execution videos below.